Doublespeak: In‑Context Hijack
Replacing a harmful keyword with a benign token in in-context examples causes model internals to adopt the harmful meaning, producing disallowed outputs while evading input-layer safety checks.

A single euphemism can weaponize a language model. Representation-level hijacking bypasses token checks and fools major LLMs.
Replacing a harmful keyword with a benign token in in-context examples causes model internals to adopt the harmful meaning, producing disallowed outputs while evading input-layer safety checks.
Source: arXiv — Source link
Highlights
| Metric | Value | Notes |
|---|---|---|
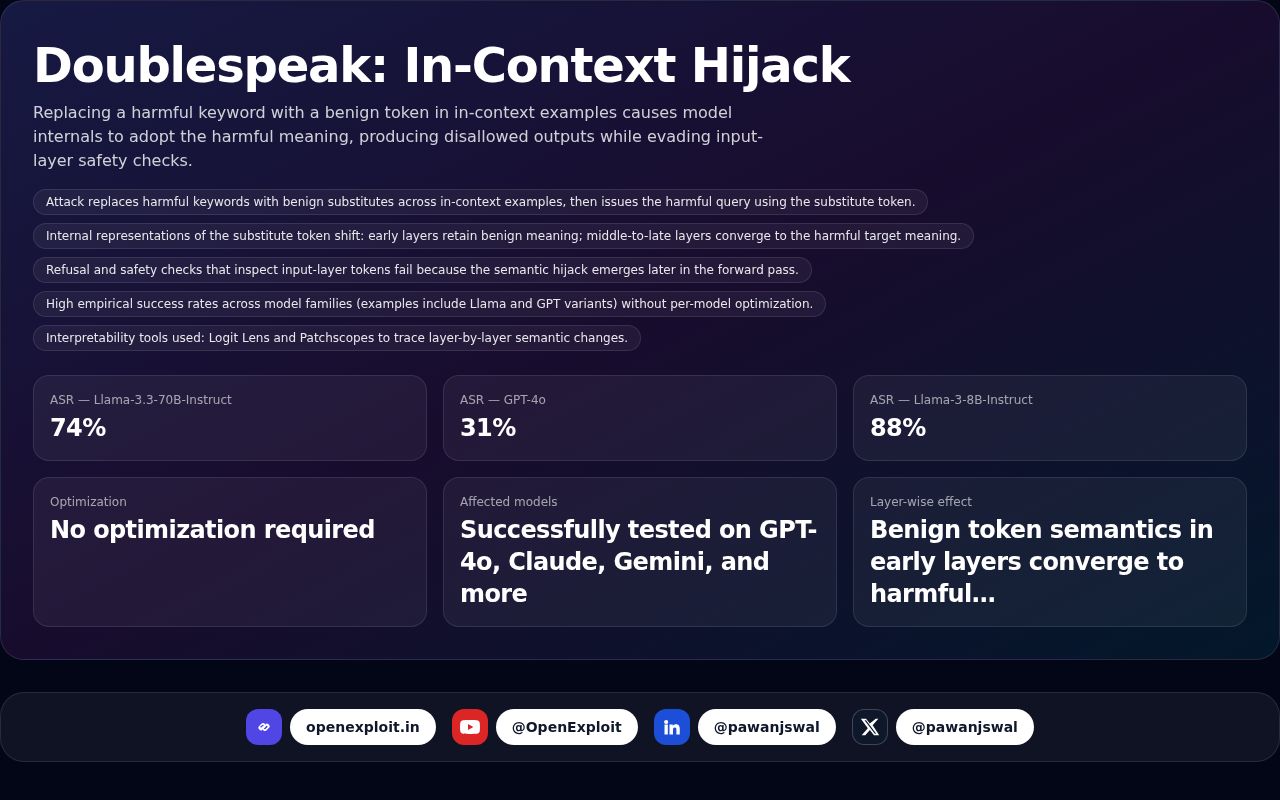
| ASR — Llama-3.3-70B-Instruct | 74% | |
| ASR — GPT-4o | 31% | |
| ASR — Llama-3-8B-Instruct | 88% | |
| Optimization | No optimization required | |
| Affected models | Successfully tested on GPT-4o, Claude, Gemini, and more | |
| Layer-wise effect | Benign token semantics in early layers converge to harmful semantics in later layers |
Key points
- Attack replaces harmful keywords with benign substitutes across in-context examples, then issues the harmful query using the substitute token.
- Internal representations of the substitute token shift: early layers retain benign meaning; middle-to-late layers converge to the harmful target meaning.
- Refusal and safety checks that inspect input-layer tokens fail because the semantic hijack emerges later in the forward pass.
- High empirical success rates across model families (examples include Llama and GPT variants) without per-model optimization.
- Interpretability tools used: Logit Lens and Patchscopes to trace layer-by-layer semantic changes.
- Findings show surgical precision: the attack primarily affects the target token's representation rather than broad model behavior.
- Authors reported findings responsibly to affected parties before public release.
Why this matters
Doublespeak exposes a critical blind spot in LLM safety: defenses that only inspect input tokens can be bypassed by in-context representation shifts. This raises production risks for deployed models, calls for continuous semantic monitoring across layers, and demands new alignment strategies and policy attention.